2022. 12. 22. 02:36ㆍC언어 복습
1. 구조체 패딩
보통 무언가를 배울 때 그것의 사용법에만 치중한 나머지 그것이 작동하는 기본 원리를 등한시하는 경우가 존재한다. 나도 그랬고 그래서 지금 복습을 통해 알게 된 내용을 이제와서라도 글로 정리하고 있는 것이다. 다들 C언어를 처음 배울 때, 구조체라는 것을 배운 기억이 분명 있을 것이라고 생각한다. 오늘 다룰 내용이 구조체에서 메모리를 할당하는 것에 대한 내용이다.
다음과 같이 구조체를 선언하고 메모리에 할당했을 때 다음과 같은 생각을 할 수 있다.
typedef struct
{
int a;
short b;
char c;
/* int - 4, short - 2, chaar - 1
모두 합해서 7바이트! */
} Sample;Sample로 변수를 하나 만들었을 때, 7바이트가 나온다고 생각할 수 있자. 하지만 실제로는 그렇지 않다. 막상 돌려보면 8바이트가 나온다.

구조체가 메모리 할당을 하는 방식을 알고 있다면 왜 이렇게 나오는지 설명할 수 있을 것이다. 이것을 패딩이라고도 부르고 바이트 정렬이라고도 하는데 우리가 사용하는 시스템은 CPU가 데이터를 읽기 위해 메모리에 접근을 해야 한다. 다만 그냥 읽어오는 것이 아니라 한 번 읽어올 때 특정 바이트 수만큼 잘라서 가져오는 것이 효율적이어서 그런 방식으로 가져온다. 여기서 말하는 특정 바이트 수가 워드의 크기를 의미한다. 지금같은 경우는 다음과 같은 방식으로 패딩이 이루어진다.

아까 전에 int, short, char를 각각 하나씩 선언한 구조체를 메모리에 할당하면 패딩 비트라는 부분 때문에 1바이트가 비게 된다. 그래서 7바이트가 아니라 8바이트가 메모리에 잡히게 되는 것이다. 그리고 이런 패딩 비트는 구조체를 선언할 때 멤버의 순서를 바꾸는 것만으로 그 크기가 바뀌게 된다. 예를 들어서 다음과 같이 구조체를 선언했다고 가정하면 다음과 같은 결과가 나온다.


총 12바이트가 나온다... 즉, 구조체를 선언할 때 멤버 변수의 선언 순서를 바꾸는 것만으로 구조체의 크기, 더 정확히 말하면 구조체를 선언할 때 사용되는 패딩의 크기가 달라진다는 것이다. 지금같은 경우는 char, int, short순으로 선언을 했고 4바이트를 기준으로 패딩이 이루어지며 그렇기 때문에 char에서 3바이트, int 이후 short에서 2바이트의 패딩이 발생하게 된다. 그래서 총 12바이트인 것이다.

그렇다면 이쯤에서 무엇을 기준으로 패딩 비트의 크기가 정해지는지 알아야 한다. 사실 나는 패딩 비트의 크기가 다음과 같이 정해지는 줄로 알고 있었다.
"가장 큰 멤버 변수의 크기를 기준으로 패딩 비트의 크기를 결정한다."
사실 앞서 두 가지의 예시를 들었는데 모두 3개의 멤버들 중에서 가장 큰 크기를 가지고 있는 int를 기준으로 패딩 비트가 정해졌다. 뿐만 아니라 char, double로 이루어진 구조체를 만들어도 double의 크기인 8바이트를 기준으로 패딩이 이루어지기 때문에 char는 8바이트로 크기가 정해지게 된다. 그렇다면 정말 이게 정답인 것일까? 아래의 코드를 보자.
#include <stdio.h>
typedef struct
{
short a;
int b;
} Sample;
typedef struct
{
short sh;
Sample s;
double d;
} Foo;
int main(void)
{
Foo f;
printf("%d\n", (char*)&f.sh - (char*)&f);
printf("%d\n", (char*)&f.s - (char*)&f);
printf("%d\n", (char*)&f.d - (char*)&f.s);
printf("%d\n", sizeof(f));
return 0;
}결과는 아래와 같이 나오게 된다.
0
4
12
24
이것을 통해 알 수 있는 것은 sh - 4바이트, s - 12바이트, d - 8바이트가 나온다는 것이다. 이 결과는 기존에 내가 구조체를 메모리에 할당하는 방식과 매우 다르다는 것을 알 수 있다. 단순히 가장 큰 멤버를 기준으로 하는 것이 아니라는 것이다. 만약 내가 알고 있던 것이 맞았다면 sh는 double을 따라서 8바이트가 되었어야 했지만 그러지 않았다... 그렇다면 도대체 왜 sh는 4바이트가 된 것일까? 아래의 코드를 보자.
#include <stdio.h>
typedef struct
{
short b;
double a;
} Sample;
typedef struct
{
short sh;
Sample s;
double d;
} Foo;
int main(void)
{
Foo f;
printf("%d\n", (char*)&f.sh - (char*)&f);
printf("%d\n", (char*)&f.s - (char*)&f);
printf("%d\n", (char*)&f.d - (char*)&f.s.a);
printf("%d\n", (char*)&f.d - (char*)&f.s.b);
printf("%d\n", sizeof(f));
return 0;
}이러면 결과는 아래와 같이 나온다.
0
8
8
16
32
다시 말해서 s에 있던 int형 멤버 변수를 double로 바꿨을 뿐인데 sh가 8바이트가 되고 s.a의 크기가 4바이트에서 8바이트로 증가한 것이다. 지금 굉장히 골 때리는 상황인 게 이 글을 쓰고 있는 지금 이 순간에도 이게 왜 이렇게 되는지 설명을 못하겠다는 것이다... 나는 지금까지 가장 큰 멤버를 기준으로 패딩을 시켜주는 것으로 알고 있었는데 그게 아니었던 것이다. 여기서 다시 한번 아래의 코드를 보자.
#include <stdio.h>
typedef struct
{
short b;
double a;
} Sample;
typedef struct
{
short sh;
Sample s;
int d;
} Foo;
int main(void)
{
Foo f;
printf("%d\n", (char*)&f.sh - (char*)&f);
printf("%d\n", (char*)&f.s - (char*)&f);
printf("%d\n", (char*)&f.d - (char*)&f.s.a);
printf("%d\n", (char*)&f.d - (char*)&f.s.b);
printf("%d\n", sizeof(f));
return 0;
}차이점이 보이는가? Foo구조체의 d라는 멤버가 double에서 int로 바뀌었다. 근데 정말 골 때리는 것은 이전에 짰던 코드와 결과가 전혀 달라지지 않는다는 것이다. 그리고 지금 이 글을 쓰고 있는 이 순간에도 저게 왜 저렇게 되는지 잘 모르겠다.
2. 2022-12-28 추가 내용
어제 새벽에 내가 다녔던 대학교의 학술 동아리 오픈 단톡방에 질문 글을 올렸고 감사하게도 선배님들의 답변이 올라왔다. 내용은 아래와 같다.
누가 답을 주셨나 모르겠는데 패딩의 핵심은 자기 다음 친구의 시작 메모리를 그 친구의 alignment에 맞춰주기 위함입니다. 예를 들어
1.에서 sh가 8이아니라 4인이유는 Sample타입의 alignment가 4이기때문에 s의 시작 메모리를 4단위로끊기위함입니다. 애초에 왜 Sample의 정렬이 4인가는 사이즈가 기준이아니라 그 구조체 자신이 메모리상의 정렬 기준이 4로 나뉘어 떨어지면 되기때문입니다. (구조체 크기는 중요하지 않음. 구조체형의Alignment가 중요) 결과적으로 Foo의크기는 2+2'+8+4'+8=24고 Foo의 Alignment는 아마 8이 될 것입니다.(=Foo형은 메모리상 8로나뉘어 떨어지는 위치에 있어야 함)
2. Sample의 구조가 변해서 Sample의 alignment가 8이 됐기때문입니다.
3. Foo의 alignment가 8이기 때문에 d뒤에 패딩 4가붙은 것입니다. 그래야 Foo foo[2]; 일때 foo[1]의 시작점이 정렬되기 때문입니다.
위의 내용을 근거로 하면 내가 들었던 의문점들이 전부 해결이 되는 것을 확인했다. 가장 큰 멤버를 기준으로 하는 것이 아니라 구조체 자체의 alignment가 얼마냐에 따라서 몇 바이트씩 끊는지가 달라지는 것이다. 가장 큰 바이트 수에 따라서 패딩이 된다고 생각했던 것은 그저 alignment가 해당 바이트 수와 동일했기 때문이었던 것이다. 이제 아래의 예시를 보자.
typedef struct
{
short a;
int b;
} Sample;
typedef struct
{
short sh;
Sample s;
double d;
} Foo;
int main(void)
{
Sample s;
return 0;
}
이해를 위해서 쉽게 표현을 해보겠다. 아래의 그림에 a가 있다. 이 친구의 자료형은 short로 크기는 당연히 2바이트다. 그렇기 때문에 이 녀석은 자신이 2바이트로 할당되기를 원할 것이다. 나는 여기서 "short의 alignment가 2바이트" 라고 표현하려고 한다.
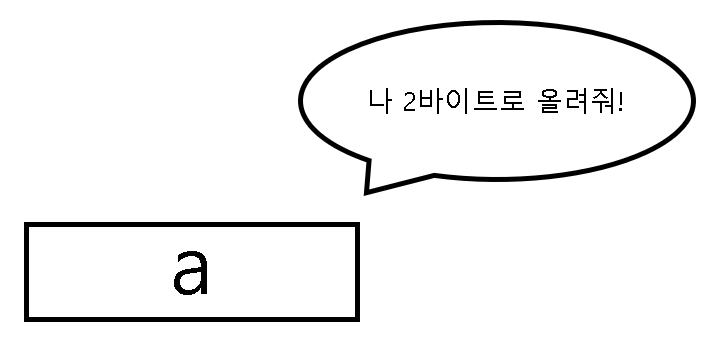
원래는 이 a가 2바이트이기 때문에 그냥 2바이트로 선언하면 되지만 그럴 수 없다. 왜냐? 자기 다음 친구의 시작 메모리를 그 친구의 alignment에 맞춰줘야 하기 때문이다. 즉, 비유적으로 표현하면 a는 자기 다음 친구인 b의 눈치를 봐야 한다는 것이다. b의 alignment가 4바이트기 때문에 b를 위해 4바이트 단위로 패딩이 가능하도록 만들어야 한다. 그렇기 때문에 아래의 그림과 같은 모양이 나오는 것이다.
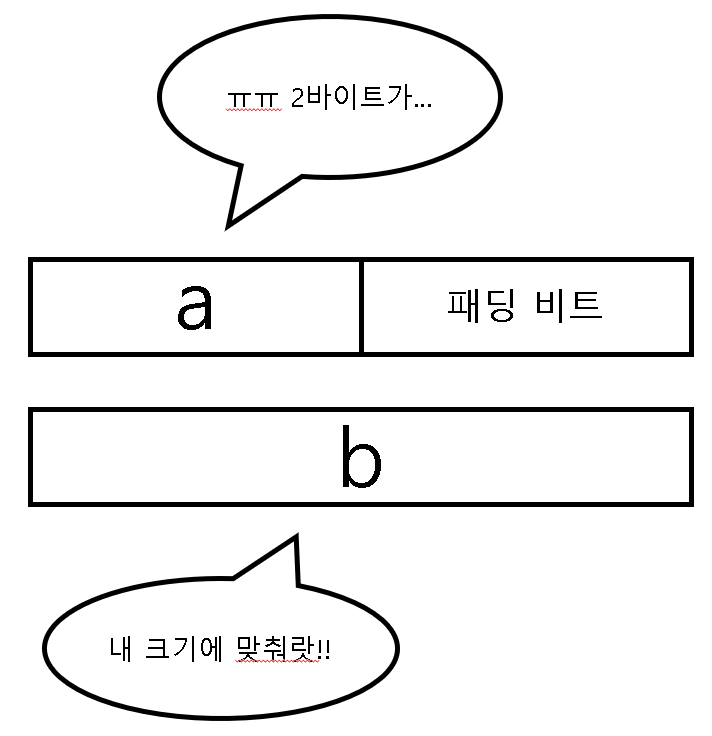
이제 Foo형 변수를 선언한다고 가정해보자. 여기서 어떻게 판정이 들어가는지 이해하는 것이 굉장히 중요하다. 우선 sh부터 보자. sh는 원래 2바이트지만 Sample s; 의 alignment가 4바이트이기 때문에 sh는 s때문에 4바이트로 정렬을 시키게 된다. 중요한 것은 단순히 메모리 크기에 따라 정렬을 시키는 것이 아니라 alignment에 따라 정렬을 시킨다는 것이다.
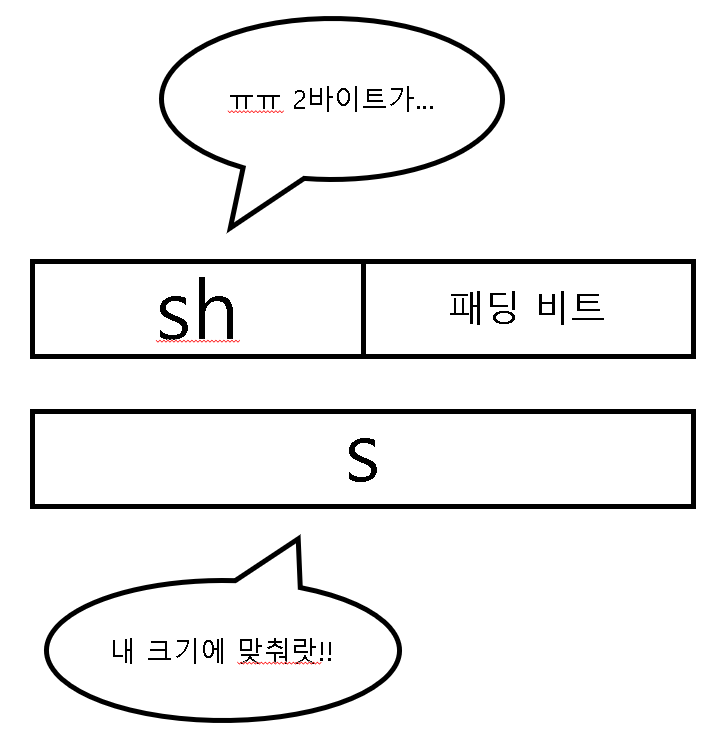
이렇게 sh가 메모리에 올라왔다. 다음은 s를 메모리에 올릴 차례인데 s도 구조체인지라 자신의 멤버를 차례대로 메모리에 올려야 한다. s의 자료형은 Sample이고 Sample의 멤버는 short a;와 int b;이기 때문에 a, b를 각각 메모리에 올려야 한다. 그럼 여기서 a를 먼저 메모리에 올린다고 가정하면...
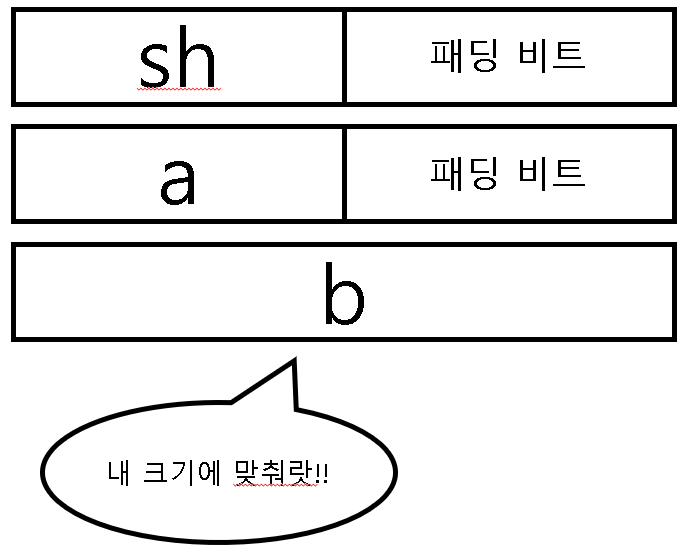
여기서 선배님께서 주셨던 답변을 그대로 적용시키면 된다. "패딩의 핵심은 자기 다음 친구의 시작 메모리를 그 친구의 alignment에 맞춰주기 위함" 이라는 내용을 근거로 a에도 그대로 적용시킨다는 것이다. 그럼 a의 다음 멤버인 b의 alignment가 4바이트이기 때문에 a역시 위의 그림처럼 4바이트로 정렬시켜야 한다는 것이다. 이제 b라는 멤버를 메모리에 올릴 차례가 되었다. 아래의 그림을 보자.
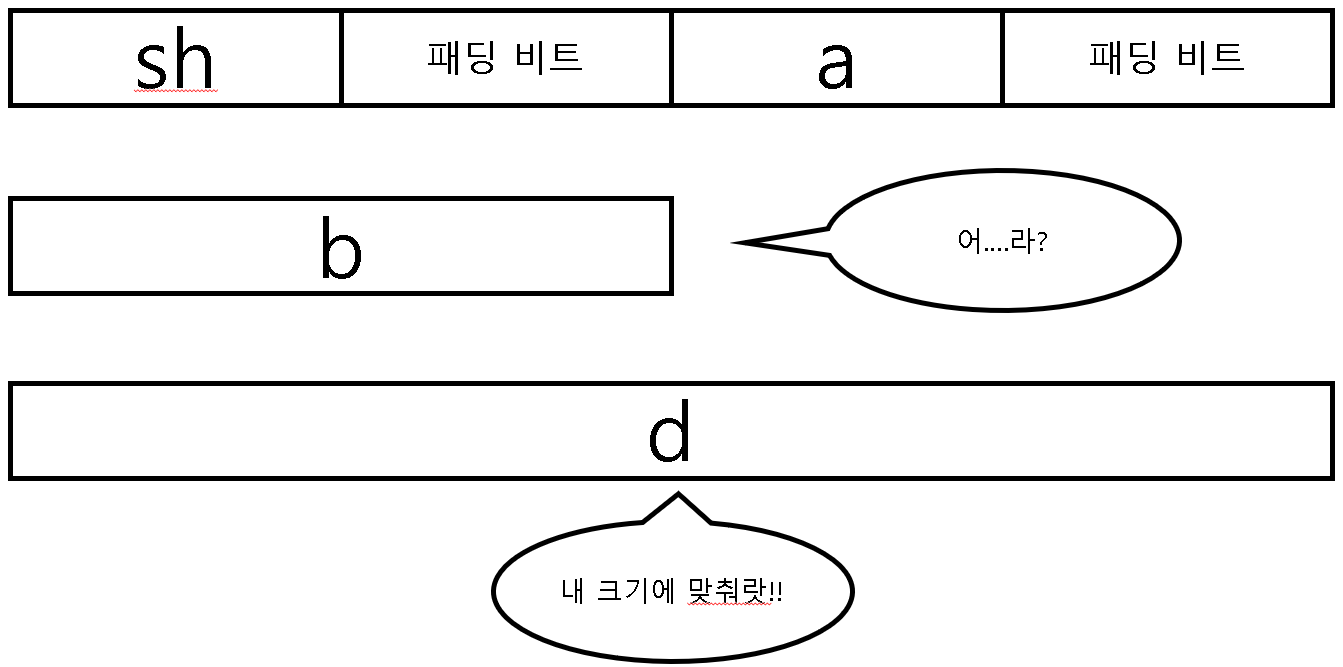
보이는가? b의 다음 멤버인 d의 alignment가 8이 나오기 때문에 8바이트를 기준으로 정렬을 시켜야 하는 상황이 나왔다. 그런데 b의 크기가 4바이트이기 때문에 8바이트로 정렬을 시키려면 sh와 a가 이미 패딩 비트를 2바이트씩 썼기 때문에 각각 4바이트가 된 상황이라서 b의 패딩 비트를 4바이트로 만들어야 8바이트씩 정렬이 되는 상황이 나오는 것이다. 이래서 총 바이트 수가 24바이트가 나온다.
그럼 이제 아래처럼 구조체의 구조를 살짝 바꾼 다음 Foo 변수를 선언해보자.
typedef struct
{
short a;
double b;
} Sample;
typedef struct
{
short sh;
Sample s;
int d;
} Foo;
int main(void)
{
Foo f;
return 0;
}우선 sh라는 변수를 선언할 때, 다음으로 오는 멤버의 alignment를 체크해야 한다. Sample의 aligment는 8바이트이기 때문에 sh는 8바이트로 정렬되어야 한다. 그리고 아까랑 마찬가지로 a역시 다음으로 오는 멤버인 double b; 의 alignment에 맞춰서 8바이트로 정렬이 된다. 그럼 아래의 그림과 같은 상황이 나오게 된다.
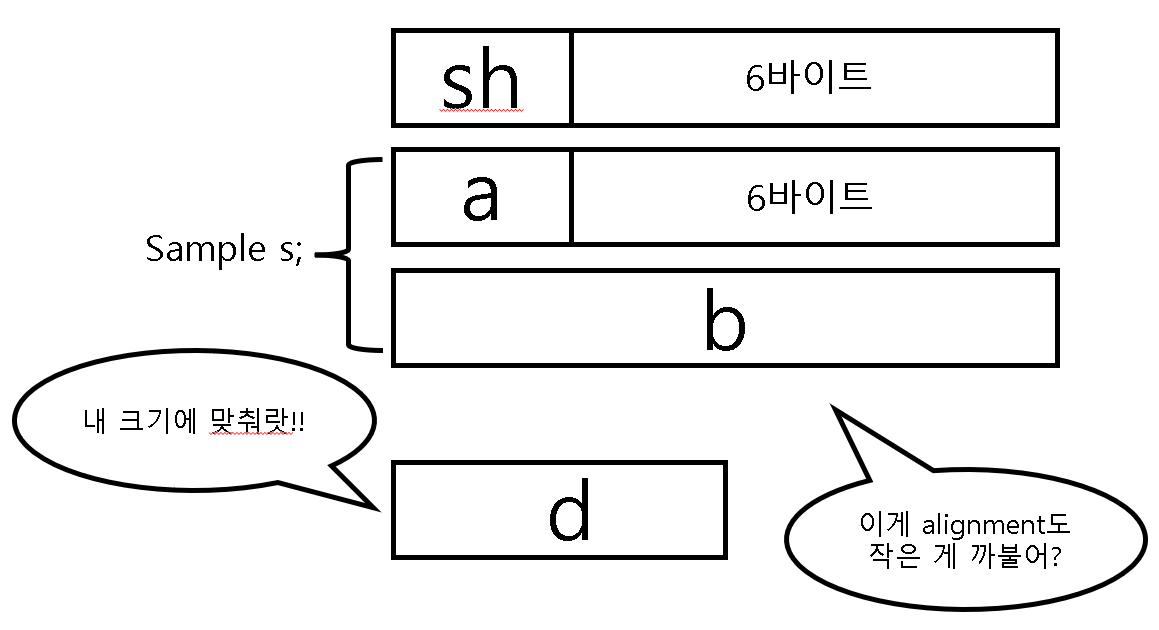
b가 메모리에 올라오기 위해서 다음 멤버인 d의 alignment에 맞춰야 하지만 b가 현재 8바이트를 기준으로 정렬되어 있는 것과 다르게 d의 alignment는 4바이트인 상황이다. 이렇게 되면 오히려 d가 8바이트에 맞춰야 한다. 8바이트를 4바이트 안에 구겨넣을 수는 없기 때문이다. 그렇기 때문에 총 바이트 수는 아래의 그림처럼 총 32바이트가 된다.
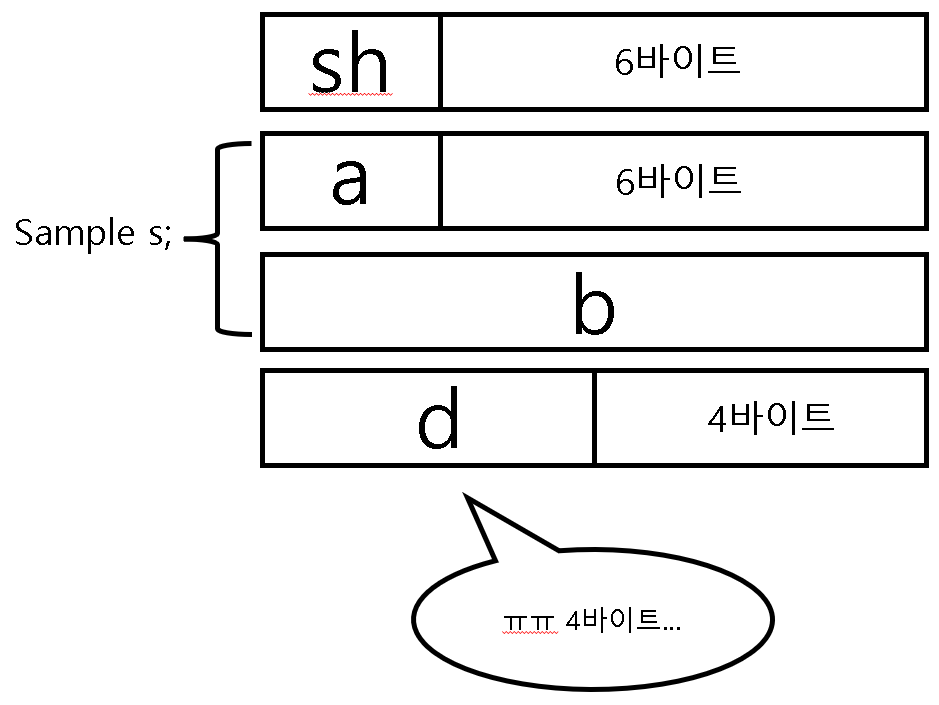
이렇게 다른 분들의 도움을 빌려서 내가 몰랐던 내용이 완전히 설명되었다. 사실 이 부분이 계속 마음에 걸려서 다음 진도를 나가는 것에 집중을 못하고 있는 상황이었는데 이제야 좀 마음에 편해지는 것 같다.
'C언어 복습' 카테고리의 다른 글
| POCU C언어 정주행 12회차 - 가변 인자 함수 (2) | 2022.12.29 |
|---|---|
| POCU C언어 정주행 11회차 - 비트 패턴, 공용체 (0) | 2022.12.26 |
| POCU C언어 정주행 9회차 - 파일 입출력, 예외 처리, 스트림 위치 (0) | 2022.12.16 |
| POCU C언어 정주행 8회차 - 스트림, 입출력 함수, 버퍼, 입력 알고리즘 (0) | 2022.12.14 |
| POCU C언어 정주행 7회차 - 문자열 함수 특징, 문자열 함수 구현 및 설명 (0) | 2022.12.12 |